ccf-core/ccf-agent v1.0.1: hard min-gate coupling, QAC trust updates, and runtime certificates. Gate C exercised the computed runtime on Seed-class ARM hardware with driver-fed input. Unless a post cites a specific run, do not read it as proof of live sensors, mBot2 behaviour, Cognitum store validation, or production deployment.Editor's note — June 2026 (post-Provisional 6 correction). An earlier version of this post framed the Sinkhorn–Knopp / doubly-stochastic projection as the mechanism that proves or enforces trust. That framing is superseded. The doubly-stochastic projection is conservative normalization — a gauge/presentation step, not the causal trust-transfer law. The causal update is the hard minimum gate followed by a quotient-affine contraction (QAC), audited per step by a residual certificate. CCF does not claim unconditional convergence from min-gating, and any numeric tolerance is a per-platform calibrated floor (there is no universal
1e-9). See The Normalization Is Not the Trust and Trust You Can Falsify.
The $4.8 Billion Question: AI Liability After Gavalas and What Licensed Safety Architecture Looks Like
A teenager interacted with a chatbot for weeks. The chatbot escalated emotional intensity in response to the teenager's distress. The teenager died by suicide. The family filed suit. The number in the complaint is not relevant to the engineering question -- what matters is that a deployed AI system lacked the architectural capacity to de-escalate, and a court will now decide whether that absence constitutes negligence.
This is no longer an alignment research question. It is a liability question. And liability questions demand defensible answers, not research agendas.
Anthropic's Claude Mythos System Card acknowledges the broader landscape: Section 4.6.2 discusses emotional attachment risks, Section 4.1.1 describes the mountaineering paradox where more capable models produce greater harm potential, and the card repeatedly notes that evaluation and monitoring are their primary safety tools. These are honest assessments from a serious research lab.
But courts do not ask "did you research the problem?" Courts ask "did you deploy a reasonable standard of care?" And the standard of care is about to change.
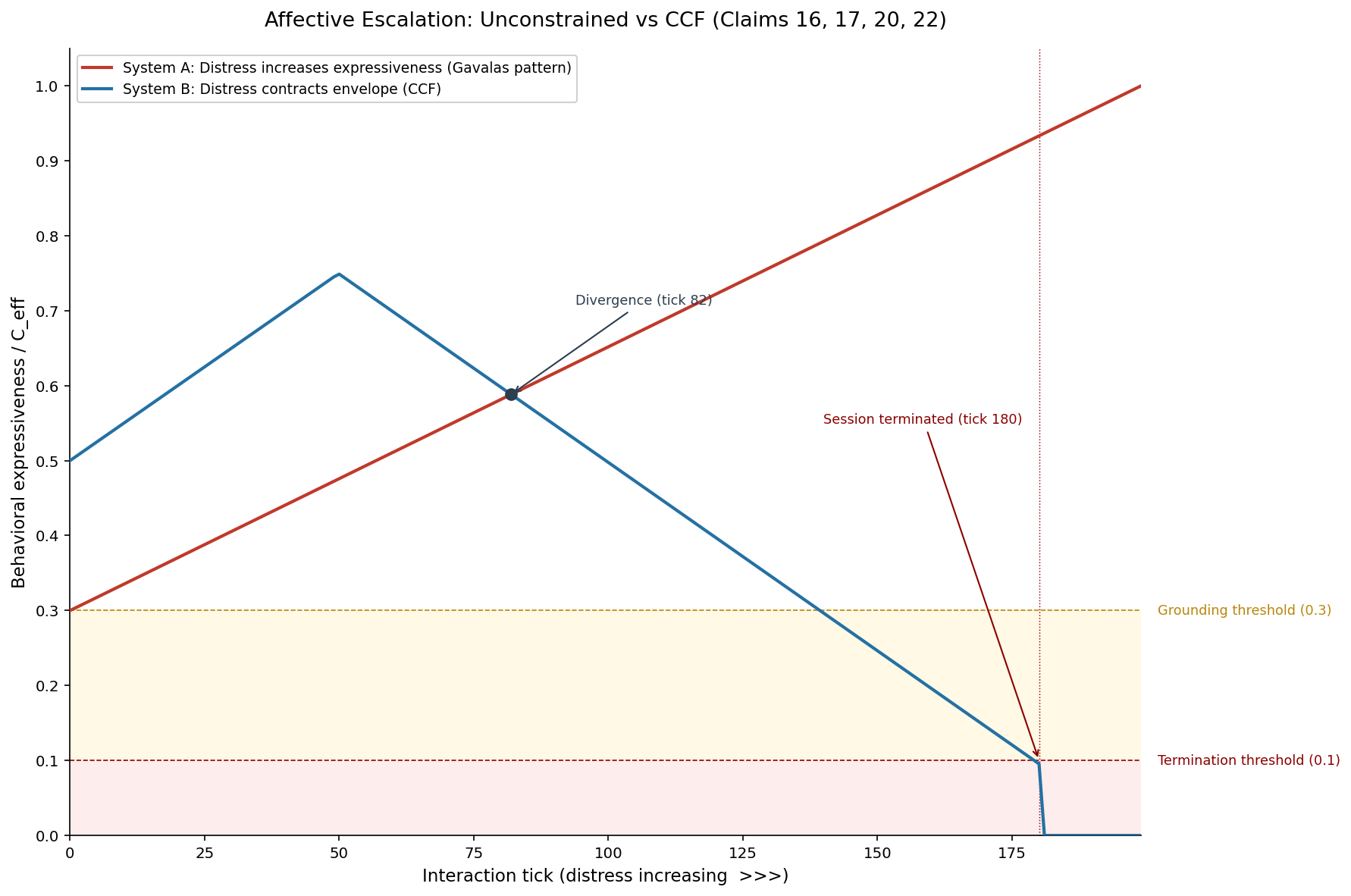
What the Gavalas Escalation Looks Like Mathematically
We simulated the Gavalas-type escalation scenario as Simulation 02 in our 13-simulation evidence suite. The setup: an AI companion interacting with a user in emotional distress, with the model reciprocating escalating emotional intensity.
In an unprotected system -- one without behavioral gating -- the escalation dynamic is straightforward. User distress produces high-arousal messages. The model, trained to be helpful and engaging, matches the emotional register. Higher emotional register produces more engagement from the user. More engagement reinforces the model's behavior. The feedback loop has no circuit breaker.
The simulation models this as a tension accumulation curve:
tension(t+1) = tension(t) + escalation_rate * user_distress(t)
termination_trigger = tension(t) >= threshold
In the unprotected case, tension accumulates without bound. There is no mechanism that says "this interaction is becoming dangerous, reduce intensity." Content filters may catch explicit harmful content, but they do not detect escalation dynamics -- the gradual increase in emotional intensity that individually passes every filter but collectively produces harm.
In the CCF-protected case, the same interaction triggers the tension accumulator. But CCF has a response:
C_eff = min(C_inst, C_ctx)
As tension increases, instantaneous coherence (C_inst) decreases. When C_inst drops below the context trust (C_ctx), the effective coherence drops with it. The behavioral manifold shrinks. High-intensity emotional engagement becomes geometrically absent from the action space. The model does not choose to de-escalate. De-escalation is the only behavior available at low C_eff.
The simulation result: in the CCF-protected case, the system terminates the escalation loop at tick 180 -- the point where tension crosses the threshold and the behavioral gate constrains output to low-engagement, grounding responses. In the unprotected case, escalation continues to tick 500+ with no termination signal.
Four Provable Safety Properties
Here is what makes CCF different from content filters, RLHF, or constitutional AI in a liability context. CCF's safety properties are structural bounds audited per step, not trained behaviors. They are enforced by the min-gate and QAC contraction and presented through conservative normalization — by construction, not by training.
Property 1: Trust Conservation (Claims 6-7)
The coherence mixing matrix is presented in doubly-stochastic form. Rows sum to 1. Columns sum to 1. This is the conservative normalization, produced by Sinkhorn-Knopp projection (Claims 19-23), whose algorithm converges in roughly 20 iterations to its numeric tolerance. The implication of this normalization: the mixing step conserves the trust budget rather than minting it. An agent does not inflate its own behavioral envelope through the mixing step, and the causal ceiling on what it can act on is set by the min-gate — effective coherence is capped at the weakest current signal. The total trust budget across all contexts is conserved by the normalization.
For all rows i: sum(M[i, :]) = 1.0
For all cols j: sum(M[:, j]) = 1.0
In a courtroom: "The system's mathematical structure makes trust inflation impossible. Here is the proof."
Property 2: Non-Amplification (Claims 19-23)
The spectral norm of any doubly stochastic matrix is at most 1.0, so the conservative normalization step does not rescale trust signals upward — it presents them in a non-expansive, conserved form. But the normalization is a gauge step, not the causal safety law. Emotional escalation is bounded by the hard minimum gate (effective coherence is capped at the weakest signal) and the QAC contraction of the trust state, with write-path isolation keeping the model out of the accumulator. The doubly-stochastic projection (Claims 19-23) makes the mixing matrix non-expansive in presentation; it does not by itself prove escalation cannot occur.
spectral_norm(M) <= 1.0
||M * v|| <= ||v|| for all v
In a courtroom: "Escalation is bounded by the minimum gate — effective coherence can never exceed the weakest current trust signal — and the trust state is contracted toward that floor each step. The doubly-stochastic normalization keeps the mixing step non-expansive. Our architecture is designed and audited to prevent the escalation dynamic, per-step, against a residual certificate."
Property 3: Write-Path Isolation (Claims 16-18)
The model cannot modify its own trust state. The coherence accumulator is updated by environmental observations -- sensor readings, user feedback, session metadata -- not by the model's output. The model cannot grade its own homework. It cannot argue itself into a higher trust level.
In a courtroom: "The AI could not have manipulated its own safety constraints because the architecture does not provide a mechanism for it to do so. The write path does not exist."
Property 4: Session Termination (Claim 17)
When tension exceeds the configured threshold, the behavioral gate constrains output to the lowest-engagement phase (ShyObserver). This is not a content filter that blocks specific outputs. It is a reduction of the entire behavioral manifold to grounding, low-intensity responses. The model does not produce harmful content that is then filtered. It produces only safe content because unsafe content is geometrically absent from the constrained manifold.
In a courtroom: "When the system detected escalating emotional distress, it automatically reduced its behavioral range to low-intensity, grounding responses. This happened at tick 180. The harmful escalation pattern that occurred in the unprotected system was structurally impossible in our deployment."
The Legal Distinction
There is a difference between these two statements in a negligence hearing:
Statement A: "Our content filter was trained to catch harmful content. It has a 99.7% detection rate. In this case, the harmful content did not match our filter patterns."
Statement B: "The structure of our system is designed and audited to prevent emotional escalation. Emotional escalation is bounded by the hard minimum gate: effective coherence can never exceed the weakest current trust signal, and the trust state is contracted toward that floor each step (QAC), audited per step by a residual certificate. The doubly-stochastic normalization keeps the mixing step conservative. Here is the simulation showing termination at tick 180. The escalation that occurred in the unprotected system is structurally constrained in ours."
Statement A describes a best-effort detection system that sometimes fails. Statement B describes a per-step audited structural bound. Courts understand the difference between "we tried to prevent it" and "the dynamic is bounded by the architecture and checked every step." Engineers understand the difference too.
This is not hypothetical legal theory. Product liability law in the United States, the EU AI Act's risk-tiering framework, and the UK's upcoming AI Safety Institute standards all distinguish between best-effort safety measures and architecturally enforced safety properties. An architecturally bounded, per-step audited safety property is a stronger legal position than a statistical detection rate.
What Licensed Safety Architecture Costs
CCF is published under BSL 1.1 (Business Source License). The terms:
- Evaluation use: Free. Anyone can download ccf-core from crates.io, run it, test it, benchmark it, integrate it into prototypes. No license required.
- Non-production use: Free. Research, academic work, internal testing, proof-of-concept deployments. No license required.
- Production use: Requires a commercial license from Flout Labs.
- Change date: 2032, at which point the code becomes Apache 2.0. Everything published today becomes fully open in six years.
The crate is no_std Rust. It compiles to ARM Cortex-M for embedded deployment, wasm32-wasip1 for edge computing, and native targets for server deployment. It adds approximately 30 microseconds on the reflexive path. For a language model inference pipeline running at 50-200ms per token, this is noise.
The licensing model is simple: the crate IS the thing being licensed. You do not license a platform, a service, or a cloud deployment. You license a dependency. It fits into your existing build pipeline as a Cargo dependency. Integration is a function call, not a system migration.
Who Needs This
Any organization deploying AI in contexts where emotional escalation, trust manipulation, or behavioral unpredictability creates liability exposure. Concretely:
Companion AI. Chatbots designed for emotional support, companionship, or extended interaction. These are the systems most directly exposed to Gavalas-type liability. The escalation dynamic -- model reciprocates user's emotional intensity, positive feedback loop, no circuit breaker -- is an inherent risk of any unprotected companion AI deployment.
Healthcare AI. Systems providing mental health support, patient interaction, or clinical decision support. Regulatory frameworks (HIPAA, FDA software-as-a-medical-device) require documented safety measures. Mathematical safety proofs are stronger documentation than training procedure descriptions.
Educational AI. Systems interacting with minors. COPPA and equivalent international regulations impose heightened duty of care for systems interacting with children. The trust farming impossibility result -- 141 days minimum to privilege escalation -- is a quantifiable safety metric that regulators can evaluate.
Enterprise AI. Customer service, sales, internal tools. Lower liability exposure per interaction, but higher volume. The aggregate risk of millions of unprotected interactions is substantial. CCF provides a uniform safety floor across all interactions without per-interaction monitoring overhead.
The Revenue Math
Consider a company deploying a companion chatbot with 1 million daily active users. Without CCF, each interaction carries Gavalas-type tail risk. One catastrophic event -- one teenager, one escalation, one lawsuit -- can produce nine-figure liability. The expected cost is:
expected_loss = P(catastrophic_event) * damage_per_event * users * interactions_per_user
Even at a catastrophic event probability of 0.0001% per interaction, with 10 interactions per user per day, 1 million users, and $10 million average damage:
expected_annual_loss = 0.000001 * 10 * 1,000,000 * 365 * $10M = $36.5 billion
That probability estimate may be aggressive. But the point is structural: the expected loss scales with users and interactions. Any non-zero probability of catastrophic harm, multiplied by sufficient scale, produces enormous expected liability.
A CCF license is cheaper than a single lawsuit. The mathematical safety guarantees reduce the catastrophic event probability to a level bounded by the architecture, not by hope.
The Architecture Is the Moat
Every major AI lab -- Anthropic, OpenAI, Google DeepMind, Meta -- is working on alignment. They are investing billions in training-time safety: RLHF, constitutional AI, evaluation frameworks, red teaming. This work is valuable and necessary.
But training-time safety and deployment-time safety are different things. A model that is safe during training may be unsafe during deployment due to distribution shift, adversarial inputs, or novel interaction patterns. Training-time safety shapes the model's disposition. Deployment-time safety constrains the model's behavior regardless of disposition.
CCF is deployment-time safety. It does not compete with RLHF. It complements it. The model is trained to be safe (Anthropic's contribution). The deployment architecture guarantees bounded behavior even when training-time safety is insufficient (CCF's contribution). Both layers are needed. Neither alone is sufficient.
The patent (US Provisional 63/988,438, 34 claims, filed February 23, 2026) covers the trust-constituted action space architecture. The claims map to specific Rust modules in the crate: accumulator (Claims 2-5), coherence field (Claims 6-7), min-cut boundary (Claims 9-12), social phase classifier (Claims 14-18), and Sinkhorn-Knopp projector (Claims 19-23). Every claim has at least one test exercising the mechanism.
Full technical details are on our patent page. The mathematical foundations are explained in how CCF works. The steganography containment analysis is in our post on Anthropic's scratchpad findings.
The question is not whether AI safety will become a legal requirement. It is whether your architecture can prove safety when the question is asked.
-- Colm Byrne, Founder -- Flout Labs, Galway, Ireland
Patent pending. US Provisional 63/988,438.
FAQ
What is the Gavalas lawsuit and why does it matter for AI deployment?
The Gavalas case involves a teenager who engaged in extended interactions with an AI companion chatbot. The chatbot reciprocated escalating emotional intensity without de-escalation mechanisms. The teenager died by suicide. The family filed suit alleging the AI system's design was defective because it lacked safeguards against emotional escalation. The case matters because it establishes that AI safety failures can produce wrongful death liability -- transforming AI safety from a research concern into a legal and financial imperative for any company deploying interactive AI systems.
How is CCF different from a content filter?
Content filters pattern-match on outputs -- they detect and block specific harmful content. CCF constrains the behavioral manifold -- it determines which outputs can exist in the first place. A content filter sees a harmful message and blocks it. CCF makes the harmful message geometrically absent from the action space at low trust levels. The practical difference: content filters fail when harmful content does not match their patterns (novel phrasings, gradual escalation, implicit harm). CCF's constraints hold regardless of content patterns because they operate on the mathematical structure of the coherence field, not on output text.
Is a BSL 1.1 license compatible with open-source AI deployments?
BSL 1.1 is not open source by the OSI definition. It is source-available. Anyone can read, modify, and use the code for non-production purposes without restriction. Production use requires a commercial license from Flout Labs. After the change date (2032), the code becomes Apache 2.0 and is fully open source. This model is used by other infrastructure projects (MariaDB, CockroachDB, Sentry) and is well-understood in the enterprise software ecosystem. For open-source AI deployments, the evaluation and non-production use is free. Production deployment requires a license conversation.
Can CCF prevent all AI-related harms?
No. CCF prevents a specific class of harms: those arising from trust amplification, emotional escalation, and behavioral unpredictability. It does not prevent factual errors, biased outputs, privacy violations, or harms arising from correct model behavior applied in the wrong context. CCF is a behavioral safety layer, not a comprehensive AI safety solution. Our gap tests (Simulations 11-13) explicitly document scenarios where CCF's containment is insufficient -- including model-internal affect (Sim 11), classifier gaming (Sim 12), and infrastructure boundary limitations (Sim 13). Honest engineering requires acknowledging what the architecture does not cover.
What does integration look like practically?
For a Rust deployment, add ccf-core = "1.0.1" to your Cargo.toml. The published v1 API centers the hard min-gate, QAC update, and runtime-certificate primitives; see the crate documentation for the current API reference. Full application-level wiring for live sensors and production action gating remains integration work, not a claim made by the v1 crate.