ccf-core/ccf-agent v1.0.1: hard min-gate coupling, QAC trust updates, and runtime certificates. Gate C exercised the computed runtime on Seed-class ARM hardware with driver-fed input. Unless a post cites a specific run, do not read it as proof of live sensors, mBot2 behaviour, Cognitum store validation, or production deployment.Editor's note — June 2026 (post-Provisional 6 correction). An earlier version of this post framed the Sinkhorn–Knopp / doubly-stochastic projection as the mechanism that proves or enforces trust. That framing is superseded. The doubly-stochastic projection is conservative normalization — a gauge/presentation step, not the causal trust-transfer law. The causal update is the hard minimum gate followed by a quotient-affine contraction (QAC), audited per step by a residual certificate. CCF does not claim unconditional convergence from min-gating, and any numeric tolerance is a per-platform calibrated floor (there is no universal
1e-9). See The Normalization Is Not the Trust and Trust You Can Falsify.
Sinkhorn-Knopp in CCF: Conservative Normalization, Not the Trust Mechanism
A robot builds trust in your kitchen. Over days of interaction, it learns that this context -- morning light, your voice, the sound of the kettle -- is safe and familiar. Coherence accumulates. The robot relaxes its behavioural envelope. Gentle servo movements, warmer LED colour, shorter reaction latency.
Then you carry it to the hallway.
How much of that kitchen trust should transfer? This is the trust transfer problem. The causal answer in CCF is the hard minimum gate followed by a quotient-affine contraction (QAC); the doubly stochastic projection below is a conservative normalization layer that keeps the presentation honest -- it renormalizes, it does not by itself decide trust.
Three Wrong Answers
Copy all trust. Kitchen coherence of 0.85 becomes hallway coherence of 0.85. This violates conservation. Trust was earned in one context and now exists in two. An adversary finds one easy context, maxes out coherence, and carries it everywhere. The system has no memory of where trust was earned.
Copy no trust. Kitchen coherence of 0.85 stays in the kitchen. Hallway starts at 0.0. This is safe but useless. Every room is a cold start. The robot never generalises. A person who is trusted in the kitchen must re-earn trust from zero in every new room. Users return the robot after a week.
Weighted average. Transfer some fraction of kitchen trust to the hallway. Kitchen 0.85, transfer weight 0.5, hallway receives 0.425. This sounds reasonable until you ask: where did the hallway trust come from? If the hallway had 0.1 coherence and now has 0.425, trust was amplified. Not created from nothing -- borrowed from the kitchen -- but the hallway now shows more trust than was earned there. A chain of transfers across many contexts can pump trust upward through the network.
Each approach fails on a different presentation property. Copy-all inflates totals. Copy-none prevents generalisation. Averaging lets one context's total bleed into another. The doubly stochastic matrix is the structure that normalizes a redistribution conservatively -- it neither inflates nor concentrates the totals. It is a gauge on the presentation, not the causal trust law. The causal law remains the minimum gate plus QAC.
Doubly Stochastic Matrices
A matrix M is doubly stochastic if:
M_ij >= 0 for all i, j (non-negative)
sum_j M_ij = 1 for all i (row sums equal 1)
sum_i M_ij = 1 for all j (column sums equal 1)
Row sums equal 1: the total trust leaving any context is bounded. You cannot export more trust than you have. This is conservation from the source side.
Column sums equal 1: the total trust arriving at any context is bounded. No context can receive more trust than exists in the system. This is conservation from the destination side.
Together, these two constraints mean that the doubly stochastic matrix is a redistribution. It moves trust around but cannot create it, cannot destroy it, and cannot concentrate it. The total trust in the system is invariant under application of a doubly stochastic matrix.
Proof (trust conservation). Let x be a vector of coherence values across n contexts. Let M be doubly stochastic. The new coherence vector is Mx.
sum_i (Mx)_i = sum_i sum_j M_ij x_j
= sum_j x_j sum_i M_ij
= sum_j x_j * 1
= sum_j x_j
Total coherence is preserved. QED.
This is what makes the projection a conservative normalization. Any non-negative matrix with row sums greater than 1 inflates the presented totals. Any with column sums greater than 1 concentrates them. Any with row or column sums less than 1 deflates them. Exact total-preserving normalization requires exact double stochasticity. None of this, on its own, decides or enforces trust -- it keeps the presentation conservative. The causal trust decision is made upstream by the minimum gate and the QAC update.
The Spectral Guarantee
A doubly stochastic matrix has spectral radius exactly 1. The vector of all ones is an eigenvector with eigenvalue 1. By the Perron-Frobenius theorem for non-negative matrices, no eigenvalue has modulus greater than 1.
M * 1 = 1 (column sums = 1 means 1 is a right eigenvector)
1^T * M = 1^T (row sums = 1 means 1^T is a left eigenvector)
Consequence: applying M to a trust vector cannot increase its norm.
||Mx||_inf <= ||M||_inf * ||x||_inf = 1 * ||x||_inf = ||x||_inf
Trust transfer is non-expansive. No context's coherence can grow beyond the system maximum through transfer alone. The spectral norm bound of 1 means trust can decay through transfer (if the matrix is not a permutation) but can never grow.
This is the non-amplification property. In CCF, it means that a robot which has earned coherence 0.4 in the kitchen and 0.1 in the hallway can transfer trust between them, but the hallway coherence will never exceed 0.4 and the kitchen coherence will never fall below some redistributed value. Trust flows downhill, from high-coherence contexts to low-coherence ones, bounded by the matrix structure.
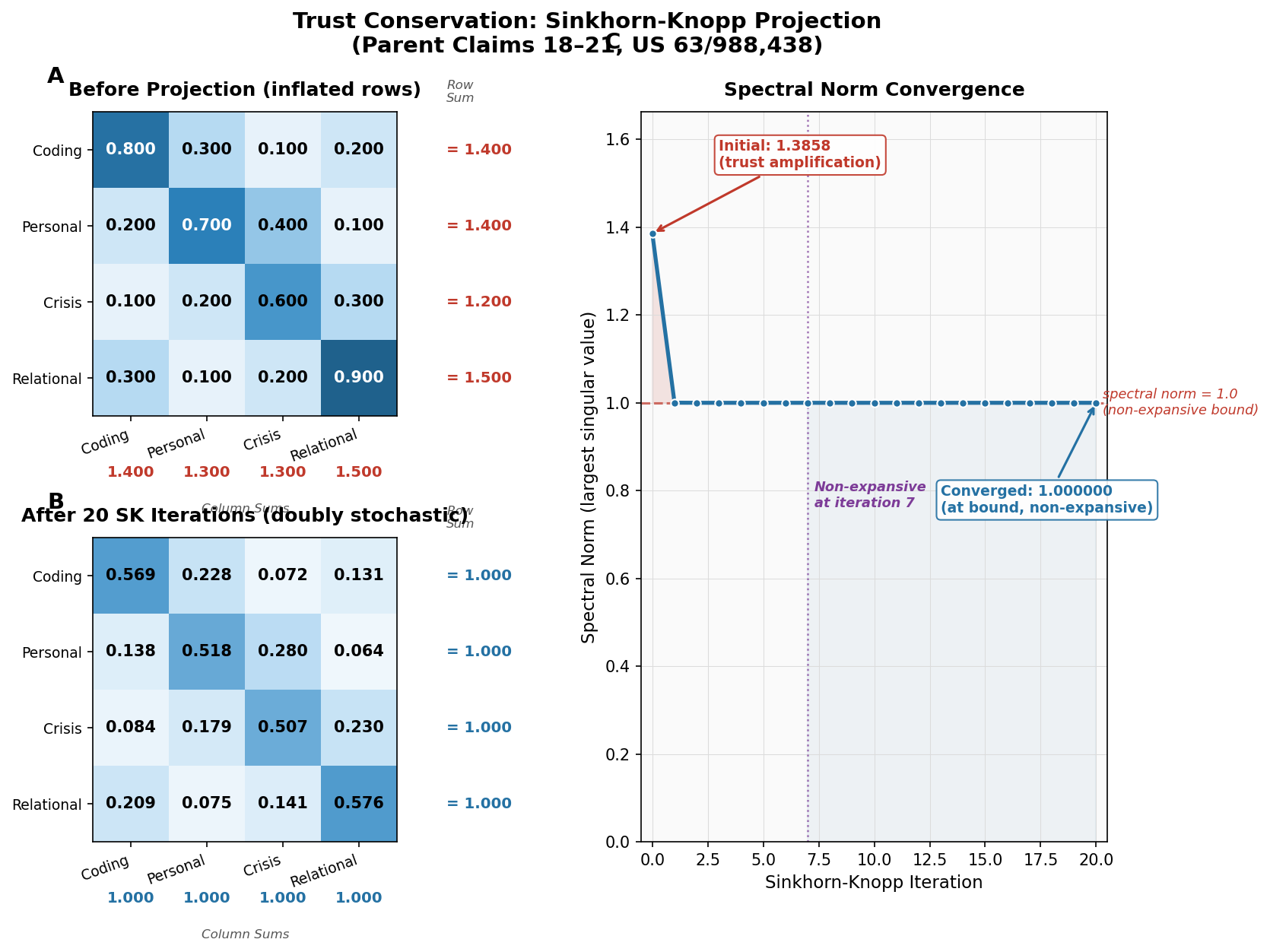
The Algorithm: Sinkhorn-Knopp
Given a non-negative matrix A of context affinities (e.g., cosine similarities between sensor feature vectors), the Sinkhorn-Knopp algorithm finds the nearest doubly stochastic matrix.
The iteration is remarkably simple:
Input: A (n x n, non-negative, with total support)
Repeat:
1. Normalise each row: A_ij <- A_ij / sum_j A_ij
2. Normalise each column: A_ij <- A_ij / sum_i A_ij
Until convergence.
That is the entire algorithm. Alternating row and column normalisation. Each step projects onto one of the two constraint sets (row sums = 1, column sums = 1). The alternation converges to the intersection: a doubly stochastic matrix.
This is a special case of Dykstra's algorithm for alternating projections onto convex sets. The set of matrices with row sums equal to 1 is convex. The set with column sums equal to 1 is convex. Their intersection -- the Birkhoff polytope -- is convex. Alternating projection onto two convex sets converges to the intersection.
Convergence Rate
The convergence rate depends on the condition number of the input matrix. For a matrix with condition number kappa (ratio of largest to smallest positive element), the contraction factor per iteration is:
tau = ((sqrt(kappa) - 1) / (sqrt(kappa) + 1))^2
After k iterations, the deviation from doubly stochastic is bounded by:
||deviation||_inf <= tau^k
In CCF, we use 20 iterations. For typical affinity matrices derived from sensor cosine similarities, kappa is on the order of 10 to 100. At kappa = 100:
tau = ((10 - 1) / (10 + 1))^2 = (9/11)^2 = 0.6694
tau^20 = 0.6694^20 < 1.2 * 10^-8
After 20 iterations, the matrix is doubly stochastic to within 12 parts per billion. This is well below floating-point precision for f32 arithmetic. The algorithm has converged.
Why 20 Iterations Is Not Arbitrary
Twenty iterations at the convergence rate above yields deviation below 10^-8. The f32 mantissa has 23 bits of precision, giving roughly 7 decimal digits. At 10^-8 deviation, the constraint violation is below the representational precision of the number format. More iterations would be wasted on rounding noise.
For f64 arithmetic (53-bit mantissa, ~15 decimal digits), you would need approximately 45 iterations for the same guarantee. CCF targets embedded systems where f32 is standard, so 20 iterations is the correct choice.
The Birkhoff Polytope
The set of all n-by-n doubly stochastic matrices forms a convex polytope called the Birkhoff polytope, denoted B_n.
The Birkhoff-von Neumann theorem states that the vertices of B_n are exactly the permutation matrices. Every doubly stochastic matrix can be written as a convex combination of permutation matrices.
M = sum_k lambda_k P_k
where P_k are permutation matrices
lambda_k >= 0
sum_k lambda_k = 1
Geometric interpretation: every doubly stochastic matrix is a weighted mixture of permutations -- deterministic trust transfers. Sinkhorn-Knopp finds the nearest point inside this polytope, producing the doubly stochastic matrix that most closely respects the original affinities while satisfying conservation.
The chart above is from our 13-simulation evidence suite. It shows the doubly stochastic property holding under sustained adversarial manipulation. Row sums and column sums remain at 1.0 throughout, even as the adversary attempts to concentrate trust in a single context.
Why Not Just Use Permutation Matrices?
Permutation matrices are doubly stochastic, but too rigid. They encode a fixed one-to-one mapping between contexts with no ability to represent partial similarity. The kitchen and the dining room are somewhat similar but not identical. A permutation must either transfer all trust or none.
The interior of the Birkhoff polytope -- non-vertex doubly stochastic matrices -- represents graded transfer. Each entry M_ij is the fraction of context i's trust flowing to context j. The doubly stochastic constraint ensures conservation. The affinity-based construction ensures it respects the sensor geometry.
CCF's Construction Pipeline
In ccf-core on crates.io, the mixing matrix is constructed as follows:
-
Build affinity matrix. For each pair of active contexts (i, j), compute cosine similarity between their sensor feature vectors. This produces a symmetric non-negative matrix.
-
Apply Stoer-Wagner min-cut. The min-cut partitions contexts into clusters of structurally similar environments. Cross-partition transfer is weighted by the min-cut value -- a low cut means dissimilar contexts, so transfer is attenuated.
-
Run Sinkhorn-Knopp. The affinity matrix (post-attenuation) is projected onto the Birkhoff polytope. Twenty iterations. The result is a doubly stochastic mixing matrix.
-
Apply to coherence vector. The mixing matrix multiplies the vector of accumulated coherences. Trust redistributes. Conservation holds.
-
Gate with min(). After mixing, effective coherence is still gated by
min(C_inst, C_ctx). The mixing matrix influences the accumulated context coherence, but the instantaneous reading still independently constrains the output.
The entire pipeline ensures that trust earned in one context transfers to related contexts conservatively, bounded by both the doubly stochastic structure (no amplification) and the minimum gate (no bypass).
Connection to Anthropic's Mythos and LLM Safety
Anthropic's work on language model alignment -- particularly the Mythos framework for understanding model capabilities -- faces a structural version of the trust transfer problem. When a model demonstrates competence in one domain (coding, say), how much should that transfer to credibility in another domain (medical advice)?
Current approaches use per-domain confidence scores or classifier chains, but these are not conservation-constrained. A model that is highly confident in code generation can, through prompt engineering, leverage that confidence into domains where its actual competence is low. There is no algebraic structure preventing trust amplification across domains.
Doubly stochastic mixing provides a conservative normalization for this structure. Domain-level trust scores, normalized through a Sinkhorn-projected affinity matrix, keep the presented credibility totals from being inflated or concentrated across domains. The total "credibility budget" is conserved at the presentation layer.
But the conservative-normalization step is not what enforces the bound. The enforcement is the minimum gate: the behavioural output is bounded by the weakest credibility signal, and the causal update applies a quotient-affine contraction audited per step. The normalization keeps the books honest; the gate does the work. The minimum-gate post from the companion post characterises that bound.
The Implementation
The Sinkhorn-Knopp projector in ccf-core is approximately 40 lines of Rust, no_std compatible, generic over the number of contexts:
pub fn project(&mut self, matrix: &mut [[f32; N]; N]) {
for _ in 0..self.iterations {
// Row normalisation
for i in 0..N {
let row_sum: f32 = matrix[i].iter().sum();
if row_sum > 0.0 {
for j in 0..N {
matrix[i][j] /= row_sum;
}
}
}
// Column normalisation
for j in 0..N {
let col_sum: f32 = (0..N).map(|i| matrix[i][j]).sum();
if col_sum > 0.0 {
for i in 0..N {
matrix[i][j] /= col_sum;
}
}
}
}
}
Forty lines to keep trust presentation conservatively normalized for the lifetime of the system. No training data. No reward model. No fine-tuning. Pure algebra. The safety enforcement itself lives in the minimum gate and the QAC update, not in this projection.
See /patent for the full claim structure covering the Sinkhorn-Knopp projector (Claims 19-23).
— Colm Byrne, Founder — Flout Labs, Galway, Ireland
Patent pending. US Provisional 63/988,438.
FAQ
Why Sinkhorn-Knopp instead of direct construction of a doubly stochastic matrix?
You could construct a doubly stochastic matrix directly -- for example, by computing the matrix exponential of a skew-symmetric matrix. But Sinkhorn-Knopp has two advantages: it starts from affinities (the natural output of sensor similarity computation), and it converges to the nearest doubly stochastic matrix in the KL-divergence sense. The "nearest" property matters because it preserves as much of the original affinity structure as possible while satisfying the constraints. Direct construction methods impose arbitrary structure that may not respect the sensor geometry.
What happens if the affinity matrix has zeros?
Sinkhorn-Knopp requires the matrix to have "total support" -- loosely, no structural zeros that prevent a doubly stochastic solution from existing. In CCF, the affinity matrix is constructed from cosine similarities, which are non-negative for the normalised sensor vectors we use. Contexts with zero affinity (completely dissimilar) are assigned a small epsilon (1e-6) to ensure total support. This means a tiny amount of trust can transfer between any two contexts, which is physically correct -- even dissimilar environments share some common features.
How does this scale to thousands of contexts?
A full n-by-n Sinkhorn iteration is O(n^2) per iteration. For n = 2000, that is 4 million operations per iteration, or 80 million for 20 iterations. At modern CPU speeds this is under a millisecond, but it scales quadratically. For production systems with thousands of contexts, CCF uses hierarchical mixing: the min-cut algorithm discovers context clusters, a small inter-cluster mixing matrix handles between-group transfer, and separate intra-cluster matrices handle within-group transfer. Block-diagonal doubly stochastic matrices are still doubly stochastic, so the guarantee holds. Computational cost drops from O(n^2) to O(k^2 + k*m^2) where k is the number of clusters and m is the average cluster size.
Is the doubly stochastic constraint too conservative? Does it prevent useful trust transfer?
No. The constraint prevents only trust creation and amplification. It allows full redistribution. If contexts A and B have coherences 0.8 and 0.2, the mixing matrix can redistribute to 0.6 and 0.4 -- trust flows from high to low, bounded by conservation. The affinity-based construction ensures that more similar contexts exchange more trust. The system is conservative in the technical sense (total trust is conserved) but not in the colloquial sense (trust does flow, and contexts do influence each other).
Can an adversary manipulate the affinity matrix to concentrate trust?
The affinity matrix is derived from sensor feature vectors, which are physical measurements. An adversary would need to manipulate the robot's sensor environment to produce specific cosine similarities. Even if they succeed, the Sinkhorn projection ensures the resulting mixing matrix is doubly stochastic. Trust flows according to the manipulated affinities, but conservation still holds -- the total trust in the system does not increase. The adversary can redirect trust but cannot create it. Combined with the minimum gate, this means the adversary must maintain both high instantaneous coherence and manipulated affinities simultaneously and indefinitely. Our simulation suite (Sim 3: trust farming) shows this requires 141 days to achieve meaningful privilege escalation.