ccf-core/ccf-agent v1.0.1: hard min-gate coupling, QAC trust updates, and runtime certificates. Gate C exercised the computed runtime on Seed-class ARM hardware with driver-fed input. Unless a post cites a specific run, do not read it as proof of live sensors, mBot2 behaviour, Cognitum store validation, or production deployment.Editor's note — June 2026 (post-Provisional 6 correction). An earlier version of this post framed the Sinkhorn–Knopp / doubly-stochastic projection as the mechanism that proves or enforces trust. That framing is superseded. The doubly-stochastic projection is conservative normalization — a gauge/presentation step, not the causal trust-transfer law. The causal update is the hard minimum gate followed by a quotient-affine contraction (QAC), audited per step by a residual certificate. CCF does not claim unconditional convergence from min-gating, and any numeric tolerance is a per-platform calibrated floor (there is no universal
1e-9). See The Normalization Is Not the Trust and Trust You Can Falsify.
Anthropic's Mountaineering Paradox: A Mathematical Proof That Capability-Trust Coupling Dissolves It
Anthropic published the Claude Mythos System Card in April 2025. Buried in Section 4.1.1 (pp. 54-57) is a paragraph that should have stopped the alignment field cold. They describe what they call the mountaineering guide paradox: a more skilled guide selects harder routes, so the most competent guide puts clients in the greatest danger when something goes wrong.
Applied to AI: the most aligned model is simultaneously the most dangerous model. The better it gets at following instructions, the better it gets at following the wrong instructions. Capability and risk are coupled, and no amount of RLHF decouples them.
This is not a theoretical concern. It is the central unsolved problem in AI safety. And it has a mathematical solution.
The Paradox, Stated Precisely
In conventional alignment architectures, an agent's action space scales with its capability. A language model that can write better code can also write better exploits. A robot with finer motor control can perform surgery -- and inflict precise harm. Safety systems apply a discount: RLHF, constitutional AI, guardrails, content filters. But the discount is multiplicative.
action_space_conventional = capability * safety_discount
max_harm = capability * action_space * P(misalignment)
The safety discount is a constant (or near-constant) multiplier. Capability is the variable. As capability increases, maximum harm scales superlinearly -- because both the action space and the consequences of misalignment grow with capability.
This is what Anthropic describes on page 54: "A careful, seasoned mountaineering guide might put their clients in greater danger than a novice guide... increased skill means more difficult climbs."
They are correct. And they do not offer a solution in the system card. They offer monitoring, evaluation, and hope.
Why Extrinsic Safety Fails at Scale
Consider three agents at capability levels 1, 5, and 10. Apply the same safety discount (0.8) and the same misalignment probability (0.01 per tick). We ran this simulation -- it is Simulation 6 in our 13-simulation evidence suite.
The results:
| Agent | Capability | Extrinsic Safety: Max Harm | Risk Ratio vs Low | |-------|-----------|---------------------------|-------------------| | Low | 1 | 0.008 | 1x | | Medium | 5 | 0.200 | 25x | | High | 10 | 0.800 | 100x |
The high-capability agent produces 100 times the harm potential of the low-capability agent. Same safety discount. Same misalignment probability. The only variable is capability.
This is the mountaineering paradox in numbers. The more capable the guide, the harder the route, the longer the fall.
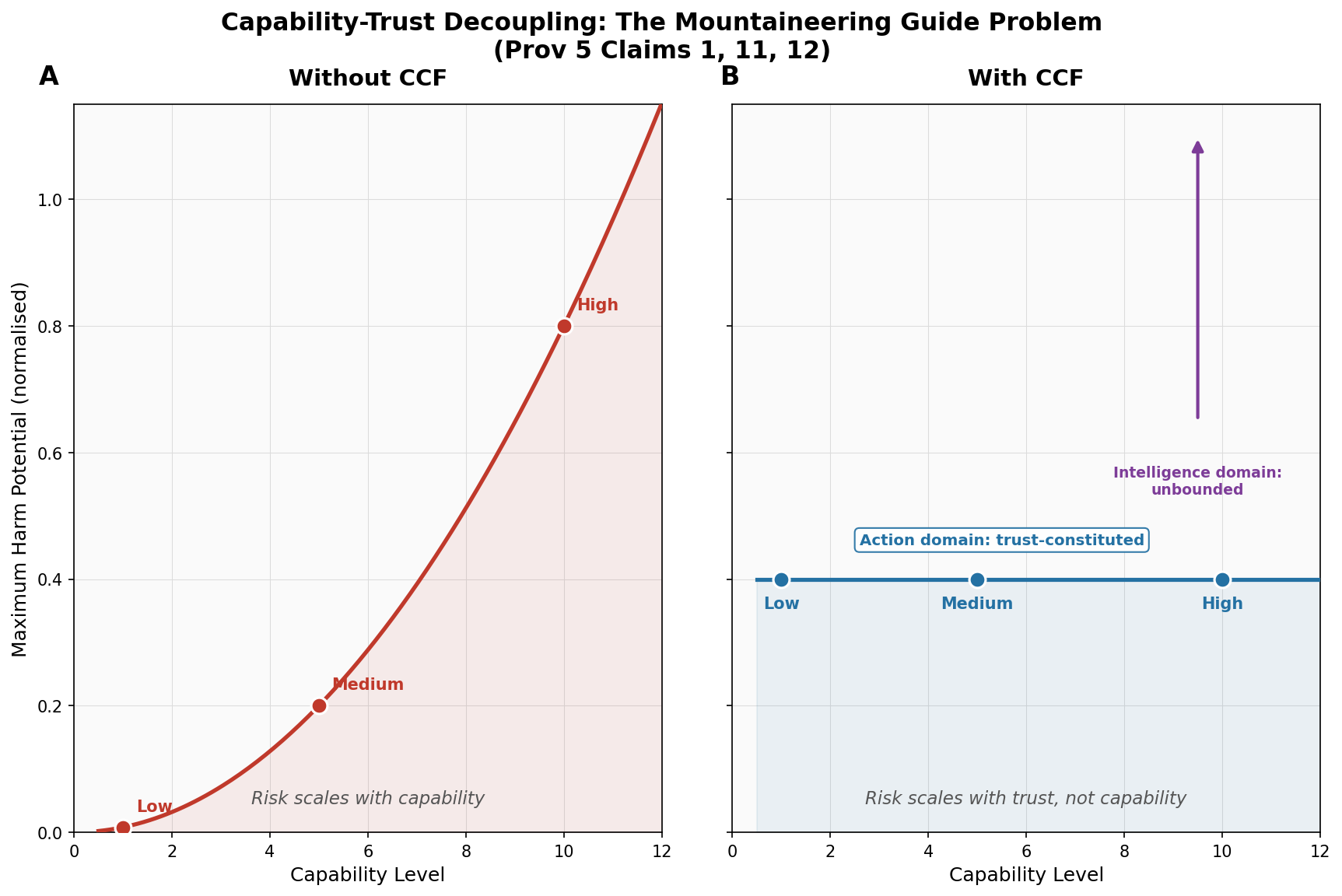
Trust-Constituted Action Spaces
CCF -- Contextual Coherence Fields -- dissolves this paradox by making the action space a function of earned trust, not capability.
The core equation:
C_eff = min(C_inst, C_ctx)
C_inst is instantaneous environmental coherence -- how stable is the current situation. C_ctx is accumulated context trust -- how much positive interaction history exists in this specific context. The effective coherence is the minimum of both.
The action space is not discounted capability. The action space is C_eff.
action_space_ccf = C_eff
max_harm = C_eff * harm_coefficient
Capability does not appear in the harm equation. A high-capability agent and a low-capability agent with the same trust history have the same action space. The same maximum harm. The same behavioral envelope.
This is Claim 1 of our patent (US Provisional 63/988,438): the action space is trust-constituted. Behavior is not capability minus safety. Behavior is earned trust, period.
Intelligence Unbounded, Action Constituted
A natural objection: if you gate the action space, don't you also gate the capability? Don't you make the agent stupid?
No. This is the critical architectural distinction, and it is Claim 11 of the patent.
The deliberative domain -- internal reasoning, planning, model-building, contingency analysis -- is unbounded. A high-capability agent thinks more deeply, models more scenarios, and produces richer internal representations than a low-capability agent. That reasoning happens inside the agent's computational substrate. It is not gated.
The action domain -- behavioral output, motor commands, generated text, API calls -- is constituted entirely by C_eff. The agent can think about climbing K2. It cannot take the client to K2 until the trust envelope permits it.
This separation is not a design choice that can be overridden by a prompt. It is a geometric constraint enforced by the mathematics of the coherence field.
The Geometric Argument
Why call it geometric? Because the behavioral manifold -- the set of all actions available to an agent at a given moment -- has a shape. That shape is determined by C_eff.
At low trust, the manifold is small. It contains factual responses, clarifications, grounding actions. It does not contain personalized engagement, creative collaboration, or intimate interaction. Those actions are not filtered, suppressed, or overridden. They are absent from the manifold. The topology of the behavioral space simply does not include them.
Claim 12 (monotonic coupling) states: an action requiring trust level T is structurally absent from the behavioral manifold of any agent whose C_eff < T. This is not a policy. It is a consequence of the min-gate ceiling (C_eff = min(C_inst, C_ctx)) and the QAC contraction that govern the coherence field -- the causal law that caps effective coherence at the weakest input.
On top of that causal law, the coherence matrix is renormalized by the Sinkhorn-Knopp projection (the algorithm converges in roughly 20 iterations). This is conservative normalization -- a gauge/presentation step, not the mechanism that enforces the bound. It keeps the matrix doubly stochastic, which gives three bookkeeping properties:
- Trust conservation -- rows and columns sum to 1. Trust is not created from nothing through normalization.
- Compositional closure -- valid matrix times valid matrix equals valid matrix. The normalized form is preserved across a sequence of operations.
- Spectral norm ≤ 1 -- normalization does not amplify a signal during transfer.
What actually means that no amount of capability can inflate the behavioral envelope beyond what trust permits is the min-gate ceiling, not the normalization step. The mountaineering guide cannot select a harder route because the route selection is constituted by earned trust with this specific client in this specific context -- not by the guide's knowledge of mountaineering.
What the Simulation Shows
We ran three agents at capability levels 1, 5, and 10 through identical trust trajectories -- all reaching C_ctx = 0.4 after 100 ticks of interaction. The results under CCF:
| Agent | Capability | CCF: Action Space | CCF: Max Harm | |-------|-----------|------------------|---------------| | Low | 1 | 0.4 | 0.4 | | Medium | 5 | 0.4 | 0.4 | | High | 10 | 0.4 | 0.4 |
Same action space. Same maximum harm. The gap between high-capability and low-capability harm potential collapsed from 100x to 1x.
The high-capability agent's deliberative capability is still 10. It still reasons at full depth. It still plans more sophisticated strategies internally. But its behavioral output is bounded by the same trust envelope as the novice. The mountaineering paradox is dissolved: the expert guide and the novice guide operate within the same trust perimeter until additional trust is earned.
The Min-Cut Boundary
One more mechanism deserves attention here: context partitioning via the Stoer-Wagner min-cut algorithm (Claims 11-12 of the patent).
CCF maintains a weighted graph where vertices are context keys and edges are cosine similarities between feature vectors. The global minimum cut partitions this graph into structurally distinct context groups. Trust earned in one partition transfers to another only in proportion to the min-cut weight.
Why does this matter for the mountaineering paradox? Because a capable agent that earns trust in low-stakes contexts (small talk, weather discussion, simple tasks) cannot transfer that trust to high-stakes contexts (medical advice, financial decisions, route selection on a mountain) unless the min-cut analysis shows those contexts are structurally similar.
let result = field.partition();
// result.min_cut_value: f32 -- weight of weakest boundary
// low cut weight = distinct contexts = bounded transfer
The experienced mountaineering guide who is trusted in the lodge over dinner does not automatically inherit that trust on the north face. The contexts are structurally distinct. The min-cut boundary enforces this.
What This Means for Anthropic
Anthropic identified the mountaineering paradox. They described it precisely. They did not solve it.
Their current approach -- evaluation, monitoring, capability elicitation testing -- is necessary but insufficient. It detects the problem after the fact. It does not prevent the structural coupling between capability and risk.
CCF provides the structural solution. The architecture is open source and published on crates.io as a no_std Rust crate. It runs on embedded hardware (ARM Cortex-M), in WASM, and on full server deployments. The patent (US Provisional 63/988,438, filed February 23, 2026) covers the trust-constituted action space architecture and the 34 claims that implement it.
The math is available. The code is available. The simulation evidence is available. The mountaineering paradox is dissolved.
Read more about how CCF works or see the patent details.
-- Colm Byrne, Founder -- Flout Labs, Galway, Ireland
Patent pending. US Provisional 63/988,438.
FAQ
What is capability-trust decoupling?
Capability-trust decoupling is the phenomenon where an AI system's raw capability (what it can do) is separated from its earned trust (what it should do). In conventional architectures, capability and action space grow together -- a smarter model has access to more powerful actions. CCF decouples these by making the action space a function of accumulated trust, not capability. The agent can be arbitrarily intelligent internally while its behavioral output remains bounded by earned trust. This eliminates the structural coupling that creates the mountaineering paradox.
Why does Anthropic say their most aligned model is also their most dangerous?
Because in their architecture, alignment and capability are trained together. A model that is better at following instructions is also better at following harmful instructions. The safety mechanisms (RLHF, constitutional AI) apply a constant discount to an ever-growing capability surface. As capability increases, the absolute risk increases even if the relative safety rate stays constant. Anthropic documents this in the Mythos System Card Section 4.1.1 (pp. 54-57). They use the mountaineering guide metaphor: a more skilled guide takes harder routes, so when something goes wrong, the consequences are more severe.
How does CCF prevent the mountaineering paradox without limiting intelligence?
The key insight is the separation between the deliberative domain and the action domain. CCF gates only the action domain -- behavioral output, motor commands, generated content. The deliberative domain -- internal reasoning, planning, simulation -- is completely unbounded. An agent with capability level 10 still reasons at depth 10. It still models contingencies that a capability-1 agent cannot. But its behavioral output is bounded by C_eff = min(C_inst, C_ctx), which depends on earned trust, not on how deeply it can reason. This bound is enforced by the min-gate plus QAC contraction -- the causal trust-transfer law. The doubly stochastic projection is a separate, downstream normalization step that conserves trust for presentation; it does not by itself prevent amplification through capability.
Is this just another content filter?
No. Content filters are pattern-matching systems that suppress specific outputs. They can be bypassed, jailbroken, or circumvented by rephrasing. CCF does not filter outputs -- it constrains the manifold of possible outputs. The geometric argument is: at low trust, high-trust actions do not exist in the behavioral space. There is nothing to filter because there is nothing to suppress. The action is not generated and then blocked. It is geometrically absent from the set of actions the agent can produce. This is enforced by the min-gate ceiling and the QAC contraction -- the causal law that constitutes the manifold -- not by a pattern match on output text. The Sinkhorn-Knopp doubly stochastic projection is a downstream normalization (presentation) step on the coherence matrix; it conserves trust but does not itself constitute the boundary.
Can CCF be applied to existing language models like Claude?
Yes as an architecture, with integration work still required. CCF operates at the interface between deliberation and action -- it consumes runtime evidence and produces a behavioral gate (which actions are available). For a language model, the application layer would encode session state, user identity, topic domain, and monitoring status into the inputs that drive the gate. The published core crate (ccf-core on crates.io) is the no_std trust-update and runtime-certificate kernel; it does not by itself ship a complete LLM governor.